Das World Wide Web (im weiteren Web) ist ein verteiltes, interaktives Hypermedia-System, das im Internet angeboten wird. Es arbeitet mit dem Protokoll HTTP, das wiederum auf dem, das Internet bildende, Protokoll TCP/IP aufbaut. Das Textformat der Dokumente ist HTML.
Das Web soll die Schnittstelle des Endbenutzers zur Datenbank darstellen. Hiermit soll er Anfrageparameter an die Datenbank übermitteln können und die Ergebnisse werden mit HTML formatiert und ihm so in seinem Browser dargestellt. Hier ist speziell auch mö glich, mit Hyperlinks weitere Anfragen zu starten, so daß der Benutzer sich quasi durch die Datenbank »klickt«.
Ein Web-Browser oder Client ist ein Programm, das HTML-Dokumente anfordert und darstellt (kann er ein übertragenes Datenformat nicht darstellen, versucht er lokal einen entsprechenden Betrachter zu starten). Beim Klick auf einen Link fordert er anschließen d von dem im URL (siehe Kapitel 3.2) des Links beschriebenen Server das im URL beschriebene Dokument an.
Der Web-Server (oder HTTP-Dämon) ist ein permanent laufendes Programm, das auf eingehende TCP/IP Verbindungen antwortet und die angeforderten Dokumente sendet. Er ist normalerweise auf dem TCP/IP Port 80 installiert.
Beispiel: Ein Benutzer startet seinen WWW-Browser (z.B. Netscape oder IBM WebExplorer...) und gibt als URL ein: »http://www.informatik.uni-wuerzburg.de/info2.html«. Dann öffnet der Browser, der die Rolle des Client spielt, eine TCP/IP Verbindung zum HTTP-S erver »www.informatik.uni-wuerzburg.de« und sendet diesem folgende Anfrage:
GET /info2.html HTTP/1.0 Accept: text/plain text/html
Der HTTP-Server schickt darauf (nach dem HTTP-Header) das gewünschte HTML-Dokument.
HTTP/1.0 200 O Server: NCSA/1.0a6 MIME-Version 1.0 Content-type text/html Last-Modified: Tue Jan 17 17:32:00 1996 Content-Length: 4242 <html> <title> .... </title> ...
Es kann jedoch auch sein, daß das URL nicht auf ein statisches Dokument zeigt, sondern auf ein Programm, das erst das Dokument dynamisch generiert. In diesem Fall wird die CGI-Norm benötigt (siehe Kapitel 3.3).
URL ist eine durch internationale Netzwerke nötig gewordene Erweiterung des normalen Dateinamen-Konzeptes. Man kann mit URLs nicht nur auf eine Datei in einem Verzeichnis des lokalen Rechners zeigen, sondern auf eine Datei in einem Verzeichnis eines Rechne rs irgendwo im Internet und dabei auch noch angeben, mit welcher Methode man auf diese Datei zugreifen möchte. URLs haben also zum Grundsatz: »If it's out there, we can point at it !« [CGI01].
Das Format von URLs sieht folgendermaßen aus:
Methode:// IP-Adresse_des_Servers [:TCP/IP-Port]/Verzeichnis/Datei
Im Falle der Anbindung von RDBMS an das WWW lautet die Methode »http«, weil Hypertexte übertragen werden sollen. Das Verzeichnis zeigt in diesem Fall auf »cgi-bin«, da der Server in diesem Verzeichnis die ausführbaren CGI-Programme speichert. Als Dateiname muß der Name des auszuführenden Programmes angegeben werden.
Da nicht jedes Programm, das auch als Web-Gateway laufen soll dafür vorgesehen sein kann, Eingabeparameter vom Benutzer per TCP/IP über das Netz abzufragen, bedurfte es wiederum einer Normung, wie der Benutzer eines Web-Client die Parameter für das Program
m zunächst dem Web-Server mitteilt, und wie dieser wiederum die Parameter an das aufzurufende CGI-Programm durchreichen soll [CGI01].
Das Programm steht normalerweise im Verzeichnis »cgi-bin« unterhalb des Web-Server-Verzeichnisses. Wichtig ist, daß die Un
ixrechte (Kommando chmod), für das Programm so gesetzt sein müssen, daß es der User, auf dessen Account der Web-Server läuft, dieses auch ausführen kann.
Input für das CGI-Programm
Die Übertragung der Programm-Parameter vom Client zum Server geschieht über das URL. So wird an das URL noch ein Fragezeichen angehängt und alles hinter diesem Fragezeichen sind Parameter für das aufzurufende Gateway.
Sollen nun mehrere Parameter übertragen werden, so trennt man sie durch ein »römisches und« (&). Leerzeichen werden durch das Pluszeichen (+) ersetzt und dieser gesamte String wird vor Aufruf des Gateway-Programmes in die Umgebungsvariable QUERY_STRING kop iert.
Beispiel zum URL:
http://www.bwc.de/telefonbuch?name=Hugo+Meier&ort=Berlin&case=egal
Zugehöriger QUERY_STRING:
name=Hugo+Meier&ort=Berlin&case=egal
Die wichtigsten Umgebungsvariablen für das CGI-Gatewayprogramm:
Außerdem werden noch folgende Variablen gesetzt:
Wenn nun das CGI-Programm, aufgerufen wird, sollte es zunächst einmal klären, ob seinen Input über STDIN bekommt (Methode POST) oder in der Umgebungsvariablen QUERY_STRING (Methode GET) gespeichert ist, wobei letzteres wohl der Normalfall ist. Beim Einlesen über STDIN ist wichtig, daß kein <EOF> übertragen wird, sondern eben genau CONTENT_LENGTH-viele Zeichen.
Nun kann es seinen Input an den '&'-Zeichen auftrennen und dann die Variablenpaare <VAR>=<WERT> auswerten. Dabei sollten eventuelle '+'-Zeichen wieder durch Leerzeichen ersetzt werden und hexadezimale Sonderzeichen (%xx) zurückübersetzt werden.
Output vom CGI-Programm
Wenn nun das CGI-Programm Ausgaben für den Server machen will, muß es diese über STDOUT machen. Vor der eigentlichen Information muß jedoch ein Header stehen, der Informationen über die Art der Ausgaben gibt. Für ein HTML-Dokument lautet der Header:
Content-type: text/html
<----- leere Zeile
<HTML><HEAD>Mein Output</HEAD>
<BODY><Hier kommt der <B>CGI<B>-Output vom Programm
</BODY></HTML>
Für ein Dokument ohne HTML-Tags lautet der Header:
Content-type: text/plain
<----- leere Zeile
Programm-Ausgabe ohne HTML-Formatierung.
Zeilen mit ASCII...
...
Wenn jedoch das Script nur auf ein bestimmtes anderes Dokument zeigen möchte:
Location: gopher://gopher.ncsa.uiuc.edu/
<----- leere Zeile
Der Web-Server überträgt das entsprechende Dokument zum anfordernden Browser-Client, der das Dokument dann anzeigt.
In jedem der drei oberen Fälle fügt der Server, nach Analyse der »Content-type«-Zeile einen entsprechenden HTTP/1.0-Header vor das Dokument, ehe er es zum Browser-Client überträgt. Will man nun als Skript-Programmierer einem viel beschäftigten Server diese Arbeit ersparen, muß das Script-Programm mit »nph-« beginnen (no-parse-header). Also zum Beispiel /cgi-bin/nph-myprog. In diesem Fall muß aber natürlich das CGI-Programm für einen korrekten HTTP-Header sorgen (siehe Kapitel 3.1).
Erst in den neueren Versionen des HTML-Standards sind »Tags« (Markierungen in spitzen Klammern) für sogenannte »Forms« (Formulare) vorgesehen. Mit diesen Formularen ist es möglich, in ein HTML-Dokument Eingabefelder, Checkboxen, Druckknöpfe usw. zu plazieren und über diese vom Benutzer Informationen abzufragen.
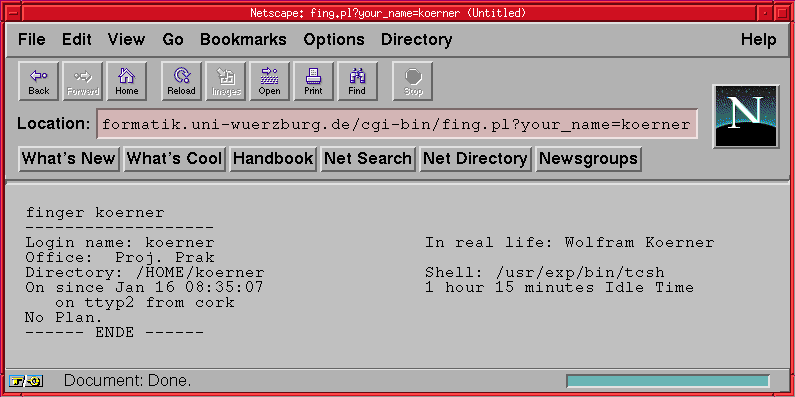
Wir betrachten hier zunächst den einfachsten Fall, daß vom Benutzer eine Zeichenkette abgefragt werden soll, nämlich der Name, der für ein Unix-finger-Kommando als Parameter verwendet werden soll (finger ermittelt den ausführlichen Namen zu einem Unix-Benutzers):
<H3>2.) CGI-Aufruf jetzt mit einer HTML-Form</H3> FINGER-Test mit CGI und HTML-Form <FORM method="GET" action="http://galway.informatik.uni-wuerzburg.de/cgi-bin/fing.pl"> Namen fuer finger: <INPUT TYPE=text VALUE="koerner" NAME=your_name> <INPUT TYPE=submit VALUE="finger"> </FORM>
Wird nun der Finger-Pushbutton gedrückt, so wird aus den Namen und Werten aller Input-Felder das nächste URL gebildet. Da im vorliegenden Fall neben dem Pushbutton nur noch das Eingabefeld mit dem Namen »your_name« vorhanden ist, lautet das URL, das der Web-Client nun verlangt:
http://galway.informatik.uni-wuerburg.de/cgi-bin/finger.pl?your_name=koerner

Der Web-Server wiederum schneidet (siehe Kapitel 3.3) alles hinter dem Fragezeichen ab und kopiert es in die Umgebungsvariable QUERY_STRING für das CGI-Programm finger.pl, das er anschließend ausführt: